leyu乐鱼体育APP官方网站
SHENZHEN CHENG XIN WEI TECHNOLOGY CO.,LTD

在数字化业务实践中,某些客有些用户的业务场景需要在短时间内能够批量创建大量的云主机,这些典型业务场景包括:
1.芯片设计,由于单机无法满足高计算需求,需要上百台云主机完成众多job的计算;
2.3D渲染,基础镜像大且需要大量云主机满足不同渲染需求;
3.抢购类业务,需要大量云主机并发以提高抢购效率。创建云主机的速度关系到这些客户的核心体验。
在创建云主机过程中,最耗时的操作为克隆虚拟机镜像这一步骤,需要将虚拟机镜像从镜像源复制一份到云盘集群。虚拟机镜像包含虚拟机上的操作系统及用户预装的软件,一个完整的镜像数据量非常大,从几GB到几十GB不等,在实践中,甚至有的镜像数据达到几百GB。创建N台云主机意味着将镜像数据复制分发N份,而且大部分公有云存储都采用三副本技术进行数据冗余,这意味着复制分发的数据量还要放大三倍。因此,在大批量创建云主机场景下,复制分发海量数据需要用户等待大量时间,这个时间往往是用户业务无法接受的。
为了缓解用户批量创建云盘主机耗时过长的问题,我们采用过镜像预灌作为过渡方案,即提前为用户克隆好系统盘镜像。该方案存在明显缺陷,不仅需要提前知晓客户的热门镜像,超额预灌也会额外占用后端存储资源。为了从根本上解决批量创建云盘主机耗时过长问题,我们设计了基于ROW(Redirect-On-Write)的克隆/快照技术,实现了写时重定向的链式克隆,达到了秒级克隆的效果。
一、快照克隆技术选型
COW(Copy-On-Write),也被称之写时复制快照技术,这种方式通常也被称为“元数据(源数据指针表)”拷贝。顾名思义,如果试图改写源数据块上的原始数据,首先要将原始数据拷贝到新数据块中,然后再进行改写。当还原快照需要引用原始数据时,快照软件会将原始数据原有的指针映射到新数据块上。

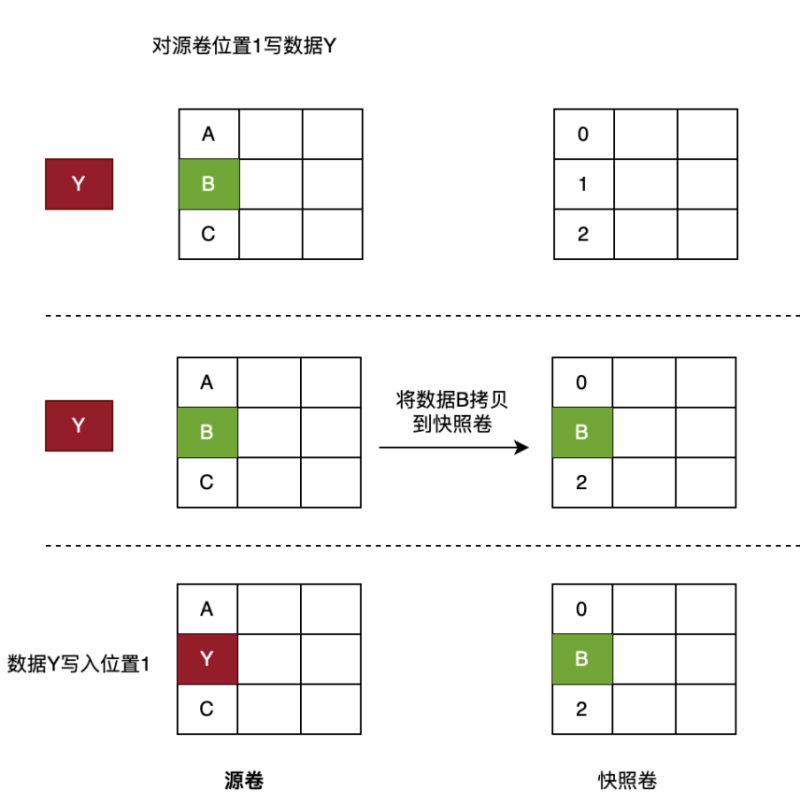
ROW(Redirect-On-Write),也被称之为写时重定向。ROW的实现原理与COW非常相似,区别在于ROW对原始数据卷的首次写操作,会将新数据重定向到预留的快照卷中,而非COW一般会使用新数据将原始数据覆盖。所以,ROW快照中的原始数据依旧保留在源数据卷中,并且为了保证快照数据的完整性,在创建快照时,源数据卷状态会由读写变成只读的。如果对一个虚拟机做了多次快照,就产生了一个快照链,虚拟机的磁盘卷始终挂载在快照链的最末端,即虚拟机的写操作全都会落盘到最末端的快照卷中。
该特征导致了一个问题,就是如果一共做了10次快照,那么在恢复到最新的快照点时,则需要通过合并10个快照卷来得到一个完整的最新快照点数据;如果是恢复到第8次快照时间点,那么就需要将前8次的快照卷合并成为一个完整的快照点数据。从这里可以看出ROW的主要缺点是没有一个完整的快照卷,其快照之间的关系是链式的,如果快照层级越多,进行快照恢复时的系统开销会比较大。但ROW的优势在于其解决了COW快照写两次的问题,所以就写性能而言,ROW无疑是优于COW的。
可以看出,ROW与COW最大的不同就是:COW的快照卷存放的是原始数据,而ROW的快照卷存放的是新数据。因为ROW这种设定,所以其多个快照之间的关系必定是链式的,因为最新一次快照的原始数据很可能就存放在了上一次快照时创建的快照卷中。另外,对于分布式系统来说,由于数据分散分布在不同存储节点上,进而提供了并发读的机会,因此,在分布式存储系统中,ROW的读写性能优于COW。
鉴于ROW与COW的对比优势,以及UDisk自身分布式部署特点,我们最终采用基于ROW的方式实现内部快照,并对UDisk的整体架构进行改进优化。为了降低批量创建云盘主机时对镜像存储集群的压力,引入Frigga模块,管理UDisk内部镜像,期望相同镜像只从镜像存储集群拷贝一次,UDisk集群内部共享。
二、方案整体架构设计
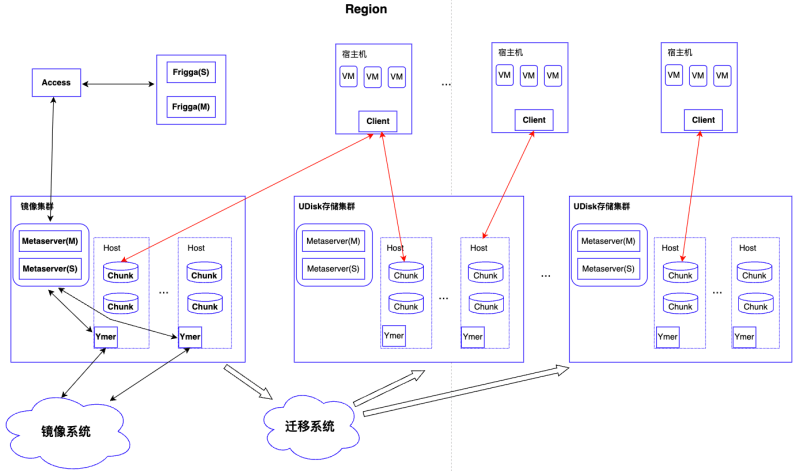
Access:UDisk接入服务,接收外部请求,并下发请求到相应存储集群中
Frigga:镜像分发管理模块,管理从镜像系统克隆的镜像。全局部署,采用主备模式,对于镜像集群中存储镜像的云盘提供新建、查询等功能;
Metaserver:UDisk存储集群元数据管理模块,存储管理集群快照克隆的链式关系和集群的路由信息;
Chunk:UDisk存储集群后端数据存储引擎,负责数据的实际读写
Client:客户端服务,UDisk存储接入模块,部署在宿主机上,负责虚机io下发到后端存储集群
Ymer:负责从镜像系统拷贝镜像到UDisk存储集群
镜像集群:特殊的UDisk存储集群,作为镜像系统Cache,后端部署与普通集群一致。该集群只存储基础镜像数据和克隆云盘数据,客户批量创建云盘主机创建的云盘系统盘都会落在该集群中,后期通过迁移系统在线将云盘系统盘打散迁移到UDisk存储集群中,迁移过程用户无感知。该集群作为基础镜像缓存池,由Frigga模块采用LRU策略淘汰冷镜像数据,只存储用户的高频热点镜像。
系统盘克隆整体流程

云主机服务下发系统盘克隆请求到Access接入服务,Access根据请求中的镜像ID向Frigga查询当前镜像是否已存在后端镜像集群。
若存在,则响应Access镜像存在,同时返回镜像对应云盘ID,Access根据云盘ID重新组织克隆请求,下发到镜像集群Metaserver服务,Metaserver接收请求执行内部克隆,更新克隆盘与镜像盘对应关系,并将关系信息同步给集群内所有Chunk服务,通知完成后向上层返回,克隆流程结束(上图绿色线+黑色线部分)。整个过程不涉及与镜像系统的交互,无数据拷贝,纯内存操作,毫秒级时间内完成。
当请求的镜像不存在时,Frigga本地内存新增镜像记录,并持久化DB。然后响应Access镜像不存在,需要从镜像系统克隆镜像。Access接收响应后,向Metaserver下发从镜像系统克隆请求,Metaserver创建镜像云盘并通知Ymer从镜像系统拷贝镜像数据,通知成功后,向上层Access返回已开始克隆,Access接收到响应后再次向Metaserver下发从镜像云盘的内部克隆请求,流程同上(上图红色线+黑色线部分)。不过此时镜像尚未克隆完成,Frigga会不断查询镜像云盘状态,直到数据拷贝完成,此时系统盘可用。相较上面流程,多了一次从镜像系统拷贝数据的过程,但也只需要一次拷贝,降低了对镜像系统的负载压力。
UDisk整体架构如何适配是核心问题,几乎涉及到UDisk所有模块的改动,下文将详细介绍如何基于ROW实现内部快照/克隆的技术细节。
三、快照/克隆云盘实现原理
为了便于理解,先介绍几个基本概念:1.UDisk提供块存储服务,对外可见的为一个个裸设备(云盘,也称为逻辑盘,lc),每块云盘对应一个全局唯一标识extern_id,每个extern_id会被分配到后端某个存储集群,且在后端集群中为extern_id分配唯一id,即lc_id;2.每个Chunk服务管理一块物理磁盘,底层以PC(4MB)为粒度管理整个物理磁盘的容量,并提供IO读写服务。
extern_id:云盘资源id,全局唯一
lc:逻辑盘,即云盘
lc_id:云盘在后端存储集群内id,存储集群内唯一
PC:逻辑存储单元
Frigga镜像管理
Frigga设计为主备模式,提高系统可用性。Frigga负责镜像的导入,后端存储集群镜像管理以及克隆调度。与Ymer配合实现UDisk存储集群间镜像共享,从镜像系统拷贝一次镜像,UDisk存储集群内数据共享,大大减轻镜像系统负载。Frigga根据LRU策略管理本地镜像,防止无效镜像/冷镜像占用存储资源,当镜像集群使用容量达到设定阈值时,根据LRU策略淘汰冷镜像。
当镜像集群容量到达使用阈值后,会根据LRU策略主动删除长时间未使用镜像。为防止单镜像集群内从单一镜像克隆过多云盘引起的访问热点问题,Frigga为每个镜像集群内的镜像设置单镜像最大支持克隆盘数量阈值,当克隆盘数量超过设定阈值后,会重新从镜像系统重新拷贝镜像。
Metaserver元数据以及路由管理
UDisk原有架构设计中逻辑盘之间相互独立,无相互关联。为了实现UDisk存储集群内部镜像共享(镜像在镜像集群中也以逻辑盘存在),以逻辑盘lc粒度管理镜像/快照/克隆盘关系,通过维护逻辑盘之间的关系实现快照的创建/克隆等操作,逻辑盘间的对应关系由Metaserver统一管理,并同步给Chunk以及Client服务。对盘多次打快照后,从不同快照克隆云盘后,Metaserver侧维护的逻辑盘之间的拓扑结构如下图所示:

从同一镜像批量克隆出多块克隆盘后,逻辑盘之间的拓扑结构如下,所有克隆盘均指向镜像云盘,只需要镜像盘从镜像系统拷贝一次,其他克隆盘的创建均为内存操作,Metaserver只需维护克隆盘到镜像之间的映射关系即可,这样极大提高了系统盘的克隆速度。

逻辑盘间的关系在Metaserver内存中都是一条条的链,链上的各逻辑盘都依赖其上层节点,从链的末尾节点可依次向上层查询直到根节点。Metaserver会将逻辑盘之间的映射关系信息实时同步给Client以及Chunk服务,Client和Chunk服务与Metaserver之间也保持心跳消息,通过心跳主动同步逻辑盘映射关系信息,防止网络分区导致的信息不一致。Metaserver通过version机制管理映射关系变化,通过比对Metaserver与Client/Chunk的version确定是否需要同步最新映射关系。
按照UDisk分布式设计原则,镜像数据被分散存储在镜像集群不同物理主机上,按原有路由策略,克隆盘读取镜像数据时,可能会存在跨机器访问的问题,增加数据读取时延,影响云主机启动速度。为此,我们优化了路由策略:克隆盘和镜像拥有相同的路由信息,克隆盘和镜像数据由相同的Chunk服务管理。这样,当云主机启动加载系统盘数据时,可以直接读取对应Chunk上的镜像数据,本地读操作,减少网络访问时延。

Client IO下发
Client作为UDisk存储集群的接入服务,负责将虚机的IO下发到存储集群不同的Chunk服务上,为了保证将克隆盘的IO下发到对应镜像所在Chunk服务上,Client侧需要获取对应克隆盘的所有映射关系,从而获取到镜像信息,以镜像的路由策略下发IO。
Chunk侧IO读/写流程优化
Chunk以PC为粒度管理磁盘,并处理IO,只有写IO时Chunk才可能分配新PC。Chunk除了从Metaserver同步逻辑盘之间的映射关系外,还维护自身管理的PC信息。对lc多次做快照后,Chunk维护的PC间拓扑结构如下图:

从同一镜像克隆出多块盘后,Chunk维护的PC间拓扑结构如下:

Chunk接收Client IO按照PC读写磁盘,每个PC对应一个pcmeta元数据,该元数据记录了PC云盘与物理盘的映射关系,其中重定向标记位(bitmap)表示该数据是否需要从父节点读取数据;每个标记位代表256k数据重定向结果,对于新建的克隆盘PC初始化时所有的bitmap都是1,表示每个256k都需要重定向读写。Client下发的IO可以由一个四元组PC Entry(lc_id, pc_no, offset, length)表示,代表要读写的逻辑盘、读写位置所属PC、PC内位置、读写大小以及数据。
读io重定向

对于读请求,首先根据四元组PC Entry确认PC是否存在,若存在,再根据pcmeta中bitmap对应位是否为1确认是否需要重定向读,bitmap为0说明读取的数据在当前PC上,直接读取数据即可。发现对应的bitmap为1就寻找父节点继续判断标记位,直到父节点的标记位为0表示不需要重定向直接读取父节点PC对应位置的数据。
写io重定向

对于写io判断首先判断PC是否存在,如果克隆的PC存在,再判断bitmap是否为1(需要重定向),如果为1就会找父节点对应的PC,先将父节点对应PC的256k数据读取出来,再与当前写io数据做合并,再写入对应的磁盘。如果克隆的PC不存在,则先创建PC,创建PC的pcmeta中bitmap设置为1,再按照之前PC存在的流程同样处理io。
四、总结
为了能够达到秒级克隆的效果,达到短时间创建大批量虚机的需求,我们采用了ROW的方法,同时利用了镜像缓存池作为热点镜像数据,提高了基础镜像克隆与内部克隆的速度与效率,能够达到5min内批量创建1000以上虚机的要求。
目前,该方案已在海外洛杉矶、新加坡机房全量开放,国内上海、广州、北京、香港等机房已针对特定客户开放。主要目标客户为短时间内有批量创建虚机需求或者大容量基础镜像的客户,可以大大缩短用户创建虚机时间。目前,可支撑用户业务高峰期批量2500台虚机的创建需求。
 留言反馈
留言反馈想了解更多产品信息详情,请您在此留言,我们会尽快回复您。
微信二维码

抖音二维码
 181 2582 6088
181 2582 6088 English
English IPv6 network supported
IPv6 network supported